I collected with web scraping 22000 category labeled articles from multiple Romanian news sites and did data exploration and text classification.
The dataset contains news articles with columns: URL, source, date, category, title, content.
There are articles published from November 2016 up to October 2021 in the dataset, however most of them are from 2020 and 2021.
The articles are evenly split among 5 categories to avoid imbalanced classifications (4400 per class): politics, social, economy, science, sports.
The articles are collected from 5 news sites: Digi24, Mediafax, Libertatea, News.ro, RFI.
I did web scraping using the requests and BeautifulSoup libraries in Python. I used a timeout between requests to not overload the servers.
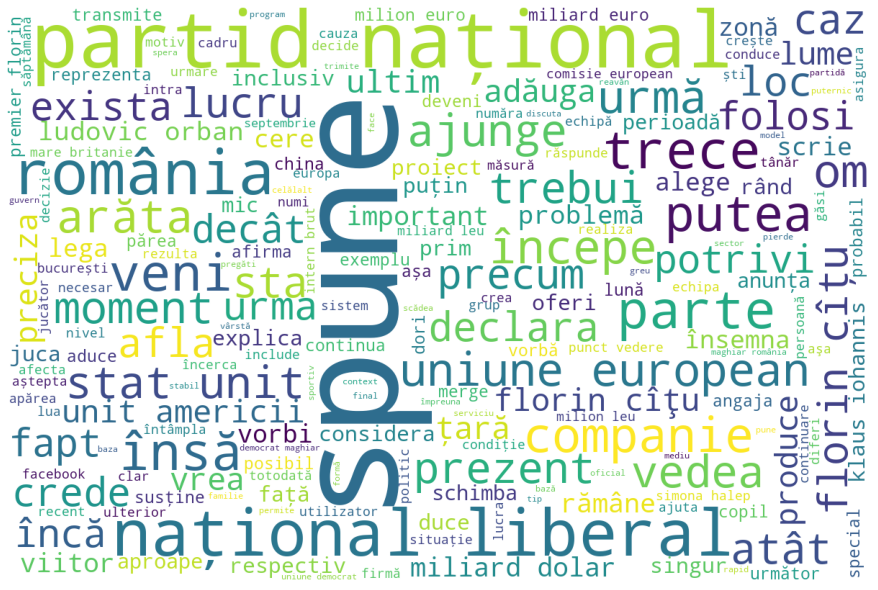
Most frequent words can be visualised with a word cloud.
We can also break it down per categories with bar charts.
In order to train a machine learning model, it is necessary to preprocess the text first. I removed punctuation, special characters, digits, lowercased and lemmatized the words. Then I vectorized the text with TF-IDF.
If we use a dimensionality reduction algorithm, such as t-SNE, we can visualize the news articles. The ones that are close to each other are supposed to be more related. I recommend opening the scatter plot below in full screen view and hovering the cursor over articles for more information.
I tested multiple machine learning classifiers. I did a grid search with 10-fold cross validation for hyperparameter tuning. SGD was the best classifier found at 86.91% cross validation accuracy. An ensemble voting of all the classifiers combined got 86.90% accuracy, tied with linear SVC. See table below.
| Classifier | Accuracy |
|---|---|
| SGD | 86.91% |
| Voting | 86.90% |
| Linear SVC | 86.90% |
| Logistic Regression | 86.61% |
| Multinomial NB | 85.83% |
| Extra Trees | 84.99% |
| K Neighbors | 84.18% |
Source code is here.